Version 2.2�@2011/09/27
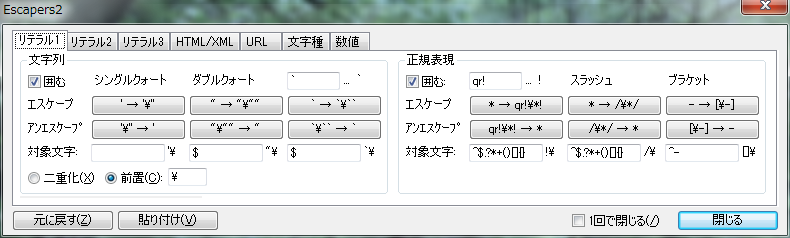
�����e�����܂��͐��K�\�����e�����̋�蕶���ƃ��^�������G�X�P�[�v���܂��B
�f���~�^
- ���e�����̋�蕶�����`���܂��B
- �悭�g�� 4 ��ނ̃f���~�^ (������̃V���O���N�H�[�g�u'�v�ƃ_�u���N�H�[�g�u"�v�A���K�\���̃X���b�V���u/�v�ƃu���P�b�g�u[]�v) �͂��炩���ߒ�`����Ă��܂��B
- ����ȊO�̃f���~�^���g���Ƃ��̓e�L�X�g�{�b�N�X�ɊJ�n�f���~�^����͂��܂��B
- �J�n�f���~�^�͔C�ӂ̕�������w��ł��܂��B��: �u`�v�uu"�v�uqq/�v�u%Q!�v
- �I���f���~�^�͊J�n�f���~�^�̖��� 1 �����ƂȂ�܂��B�������A���� 1 �������u(�v�u[�v�u{�v�u<�v�̏ꍇ�͂��ꂼ��u)�v�u]�v�u}�v�u>�v�ƂȂ�܂��B
- [�͂�] �`�F�b�N�{�b�N�X�� ON �ɂ���ƁA
- �G�X�P�[�v�Ɠ����ɗ��[�Ƀf���~�^���t������܂��B
- �A���G�X�P�[�v�Ɠ����ɗ��[�̃f���~�^����������܂��B
�Ώە���
- ���e�������ŃG�X�P�[�v�����ׂ��������`���܂��B
- �f���~�^�ƃG�X�P�[�v���� (��q) �͂��炩���ߑΏە����Ɋ܂܂�Ă��܂��B
- ����ȊO�̕������G�X�P�[�v����Ƃ��̓e�L�X�g�{�b�N�X�ɓ��͂��܂��B��: �u$�v�u$@�v�u#�v
�G�X�P�[�v���@
- [��d��] �́A�Ώە������J��Ԃ���܂��B��: �u"�v���u""�v
- [�O�u] �́A�Ώە����̑O�ɃG�X�P�[�v�������}������܂��B��: �u"�v���u\"�v
- �C�ӂ̃G�X�P�[�v�������e�L�X�g�{�b�N�X�ɓ��͂��܂��B��: �u\�v
- ���K�\���̃G�X�P�[�v���@�͑O�u�u\�v�ɌŒ肳��Ă��܂��B
�G�X�P�[�v�{�^��
- �Ώە������G�X�P�[�v���܂��B
- [�͂�] �`�F�b�N�{�b�N�X�� ON �̏ꍇ�A�����Ƀf���~�^�����[�ɕt������܂��B
�A���G�X�P�[�v�{�^��
- �Ώە������A���G�X�P�[�v���܂��B
- [�͂�] �`�F�b�N�{�b�N�X�� ON �̏ꍇ�A�����ɗ��[�̃f���~�^����������܂��B
���b�Z�[�W
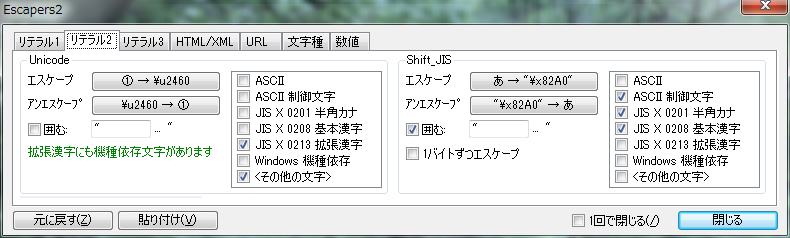
���e�������̕����� Unicode �܂��� Shift_JIS �̃G�X�P�[�v�V�[�P���X�ɕϊ����܂��B
- Unicode �G�X�P�[�v�� Java �� native2ascii �ɑ������܂��B
- Unicode �̃G�X�P�[�v���ʂ̓R�[�h�|�C���g�l�ł͂Ȃ� UTF-16 �ŃG���R�[�h���ꂽ�l�ł��B�T���Q�[�g�y�A�� 2 �̃G�X�P�[�v�V�[�P���X�ɕϊ�����܂��B
�Ώە����Z�b�g
- �ϊ��ΏۂƂ��镶���̎�ނ��`�F�b�N���X�g�̒�����I�����܂��B�����Z�b�g�̐��� ���Q�Ƃ��Ă��������B
�f���~�^
- ���e�����̋�蕶�����`���܂��B��`���@�� ���e����1 �Ɠ����ł��B
�G�X�P�[�v�{�^��
- �I�������Ώە����Z�b�g�ɑ����镶�����G�X�P�[�v�V�[�P���X�ɕϊ����܂��B
- [�͂�] �`�F�b�N�{�b�N�X�� ON �̏ꍇ�A�����Ƀf���~�^�����[�ɕt������܂��B
�A���G�X�P�[�v�{�^��
- �I�������Ώە����Z�b�g�ɑ�����G�X�P�[�v�V�[�P���X�����̕����ɖ߂��܂��B
- [�͂�] �`�F�b�N�{�b�N�X�� ON �̏ꍇ�A�����ɗ��[�̃f���~�^����������܂��B
�I�v�V����
- [1�o�C�g���G�X�P�[�v]
- 2 �o�C�g������ 1 �o�C�g���ɕ����ăG�X�P�[�v���܂��B��: �u���v���u\x82\xA0�v
- �A���G�X�P�[�v�͂��̐ݒ�ɉe������܂���B1 �o�C�g���́u\x82\xA0�v�� 2 �o�C�g���́u\x82A0�v�����l�ɃA���G�X�P�[�v����āu���v�ɖ߂�܂��B
���b�Z�[�W
Shift_JIS �ő� 2 �o�C�g�� 0x5C ���܂ށA������u�_�������v���G�X�P�[�v���܂��B
- �Ώە����́u�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�x�x�\�\�v�ł��B
- NEC �I�� IBM �g�������́u�x�v(0xED5C)�E�u�x�v(0xEE5C) �́AWindows �ł� IBM �g�������́u�x�v(0xFA78)�E�u�x�v(0xFB78) �ɓ��ꂵ�Ĉ����邽�߁A�Ώە����Ɋ܂܂�Ă��܂���B
�G�X�P�[�v�{�^��
- �Ώە����̌�Ɂu\�v��t�����܂��B
�A���G�X�P�[�v�{�^��
- �Ώە����̌�́u\�v���������܂��B
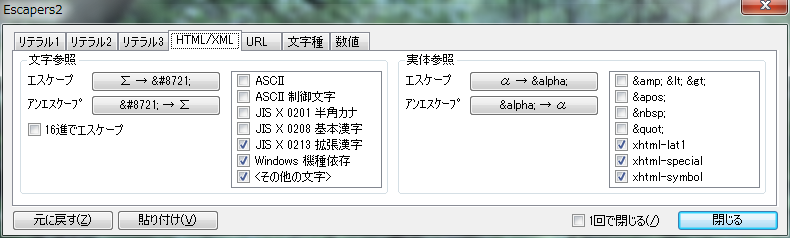
HTML/XML �������̕������Q�Ƃ܂��͎��̎Q�Ƃɕϊ����܂��B
�Ώە����Z�b�g
- �ϊ��ΏۂƂ��镶���̎�ނ��`�F�b�N���X�g�̒�����I�����܂��B�����Z�b�g�̐��� ���Q�Ƃ��Ă��������B
�G�X�P�[�v�{�^��
- �I�������Ώە����Z�b�g�ɑ����镶�����Q�Ƃɕϊ����܂��B
�A���G�X�P�[�v�{�^��
- �I�������Ώە����Z�b�g�ɑ�����Q�Ƃ����̕����ɖ߂��܂��B
�I�v�V����
- [16�i�ŃG�X�P�[�v]
- �����Q�Ƃ� 16 �i�\�L�ɂ��܂��B��: �u���v���uあ�v
- �A���G�X�P�[�v�͂��̐ݒ�ɉe������܂���B16 �i�\�L�́uあ�v�� 10 �i�\�L�́uあ�v�����l�ɃA���G�X�P�[�v����āu���v�ɖ߂�܂��B
���b�Z�[�W
������� URL �G���R�[�h�^URL �f�R�[�h���܂��B
����������
- ������������I�����܂��B�ڂ����� ecl.txt ���Q�Ƃ��Ă��������B
�G���R�[�h�{�^��
- �I�����������������ŕ������ URL �G���R�[�h���܂��B
�f�R�[�h�{�^��
- �I�����������������ŕ������ URL �f�R�[�h���܂��B
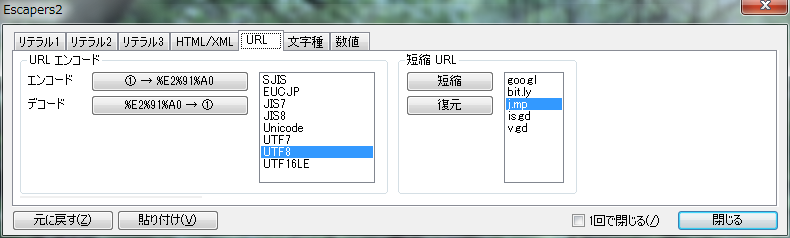
Web �T�[�r�X�𗘗p���� URL ��Z�k�^�������܂��B
�T�[�r�X
- �T�[�r�X��I�����܂��B
- goo.gl: Google �̒��� URL �Z�k�T�[�r�X�ł��B
- bit.ly: bitly �̒��� URL �Z�k�T�[�r�X�ł��B
- j.mp: bitly �̒��� URL �Z�k�T�[�r�X�ł��B
- is.gd: Memset �̒��� URL �Z�k�T�[�r�X�ł��B
- v.gd: Memset �̒��� URL �Z�k�T�[�r�X�ł��B���� URL �֔�ԑO�Ɋm�F������܂��B
�Z�k�{�^��
- �I�������T�[�r�X�� URL ��Z�k���܂��B
�����{�^��
- �I�������T�[�r�X�� URL �����܂��B
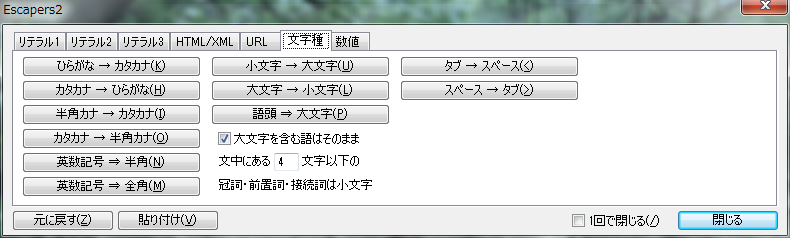
�������ϊ����܂��B
- [�Ђ炪�� �� �J�^�J�i]
- �Ђ炪�Ȃ��J�^�J�i�ɕϊ����܂��B
- [�J�^�J�i �� �Ђ炪��]
- �J�^�J�i���Ђ炪�Ȃɕϊ����܂��B
- [���p�J�i �� �J�^�J�i]
- ���p�J�i���J�^�J�i�ɕϊ����܂��B
- [�J�^�J�i �� ���p�J�i]
- �J�^�J�i�p�J�i�ɕϊ����܂��B
- [�p���L�� �� ���p]
- �S�p�̋E�L���E�p�����p�ɕϊ����܂��B
- [�p���L�� �� �S�p]
- ���p�̋E�L���E�p������S�p�ɕϊ����܂��B
- [������ �� �啶��]
- �p���������p�啶���ɕϊ����܂��B�S�p�p�����ϊ�����܂��B
- [�啶�� �� ������]
- �p�啶�����p�������ɕϊ����܂��B�S�p�p�����ϊ�����܂��B
- [�ꓪ �� �啶��]
- ������L���s�^���C�Y�ł��B�p�����̒P��̐擪��啶���ɁA�擪�ȊO���������ɕϊ����܂��B�S�p�p���͕ϊ�����܂���B
- [�啶�����܂ތ�͂��̂܂�]
- ���̃`�F�b�N�{�b�N�X�� ON �ɂ���ƁA���ɑ啶�����܂ޒP��͕ϊ�����܂���B��:�uI bought my iPad in eBay�v���uI Bought My iPad in eBay�v
- [�����ɂ��� n �����ȉ��̊����E�O�u���E�ڑ����͏�����]
- ���̃e�L�X�g�{�b�N�X�ɕ���������͂���ƁA a, aboard, about, above, across, after, against, along, alongside, among, an, and, around, as, at, before, behind, below, beneath, beside, besides, between, beyond, but, by, concerning, despite, down, during, except, for, from, in, inside, into, less, like, minus, near, nor, of, off, on, onto, opposite, or, out, outside, over, past, plus, round, save, since, so, than, the, through, throughout, till, to, toward, under, underneath, until, up, upon, via, with, within, without, yet �̂����w�肵���������ȉ��̒P��́A�����E�����������A���ׂď������ɕϊ�����܂��B
- [�^�u �� �X�y�[�X]
- �n�[�h�^�u���\�t�g�^�u�ɕϊ����܂��B�s���ȊO�̃^�u���X�y�[�X�ɕϊ�����܂��B
- [�X�y�[�X �� �^�u]
- �\�t�g�^�u���n�[�h�^�u�ɕϊ����܂��B�s���ȊO�̃X�y�[�X���^�u�ɕϊ�����܂��B
������𐔒l�ƌ��Ȃ��Ċ�ϊ����܂��B
- �����̐��l���ꊇ�ϊ��ł��܂��B�I��͈͓��̒P�ꂲ�ƂɁA���̒P�ꂪ�ϊ�����̐��l�Ƃ��ĉ��߂ł���A�ϊ�����܂��B��: [16�i �� 10�i] �̂Ƃ��A�uA 20 pounds of beef steak�v���u10 32 pounds of 48879 steak�v
�
- �ϊ����ƕϊ���̊���e�L�X�g�{�b�N�X�ɓ��͂��܂��B2 �i���� 36 �i�܂ŔC�ӂ̊���w��ł��܂��B
�ϊ��{�^��
- �\������Ă���悤�Ɋ��ϊ����܂��B
������𐔎��ƌ��Ȃ��Čv�Z���܂��B
- [Google �d��]
- ������ Google �d��Ōv�Z���܂��B
- Google �d��̏o�͌`�����ύX���ꂽ�ꍇ�A���ʂ��擾�ł��Ȃ��Ȃ�\��������܂��B�C�Â����l�͍�҂ɋ����Ă��������B�q���k�b���r
���e����2 �� HTML/XML �ł́A�ϊ��ΏۂƂ��镶���̎�ނ��`�F�b�N���X�g�̒�����I�����܂��B���X�g��̌X�̑I�������Z�b�g�ƌĂт܂��B
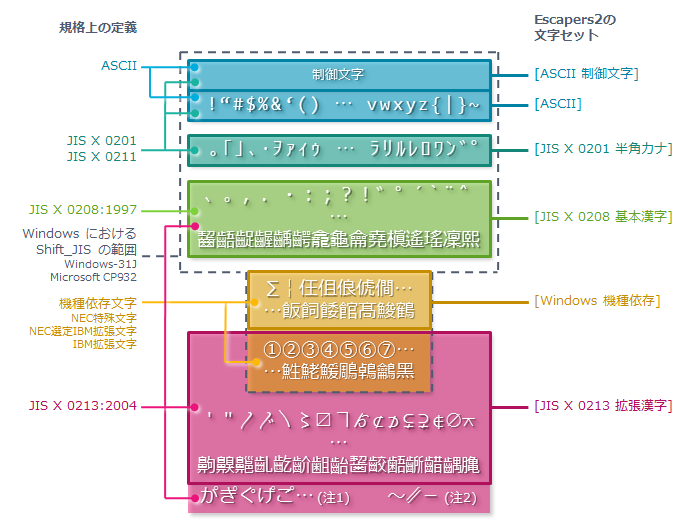
���e����2 �� Unicode �� Shift_JIS ����� HTML/XML �� �����Q�� �őI���ł��镶���Z�b�g�̓��e�͎��̂Ƃ���ł��B
����������Ȑ���
- [ASCII]
- �����锼�p�p�����ł��B���p�X�y�[�X�E���p�L�����܂݂܂��B
- [ASCII ���䕶��]
- �^�u��������s�����Ȃǂł��B
- [JIS X 0201 ���p�J�i]
- �����锼�p�J�i�ł��B
- [JIS X 0208 ��{����]
- ������S�p��������@��ˑ����������������̂ł��B�S�p�E�S�p�L���E�S�p�p�����E�Ђ炪�ȁE�J�^�J�i�E��ꐅ�������E����������܂݂܂��B
- [JIS X 0213 �g������]
- ���{��̂����� Unicode �����ł��B��O���������E��l���������E�����܂݂܂��B
- [Windows �@��ˑ�]
- Windows �̋@��ˑ������̂��� JIS X 0213 �Ɏ��^����Ă��Ȃ����̂ł��B
- [<���̑��̕���>]
- ��L�ȊO�̕��� (�n���O���Ȃ�) �ł��B
�����Ȑ���
- (��1)
- JIS X 0213:2004 �Ɏ��^����Ă��镶���̂����AUnicode �ō��������Ƃ��ĕ\���������̂́AWindows �ł͍\���v�f�P�ʂŕʌ̕����Ƃ��Ĉ����邽�߁A[JIS X 0213 �g������] �Ɋ܂܂�Ă��܂���B
- (��2)
- JIS X 0213:2004 �Ɏ��^����Ă��镶���̂����A�u�`�v(U+301C, WAVE DASH)�E�u�a�v(U+2016, DOUBLE VERTICAL LINE)�E�u�|�v(U+2212, MINUS SIGN) �́AWindows �ł� JIS X 0208-1997 �Ɏ��^����Ă���u�`�v(U+FF5E, FULLWIDTH TILDE)�E�u�a�v(U+2225, PARALLEL TO)�E�u�|�v(U+FF0D, FULLWIDTH HYPHEN-MINUS) �Ƃ��ꂼ�ꓯ�ꎋ����邽�߁A[JIS X 0213 �g������] �Ɋ܂܂�Ă��܂���B
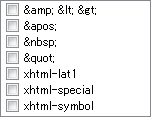
HTML/XML �� ���̎Q�� �őI���ł��镶���Z�b�g�̓��e�͎��̂Ƃ���ł��B
����������Ȑ���
- [']
- �u'�v�ł��B
- [& < >]
- �u&�v�u<�v�u>�v�ł��B
- [ ]
- ���p�X�y�[�X�ł��B
- ["]
- �u"�v�ł��B
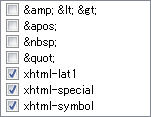
- [xhtml-lat1]
- �����A�N�Z���g�t���A���t�@�x�b�g�Ȃǂł��B���̂����u´¨±×÷°§¶�v�͊�{�����ɂ�����܂��B
- [xhtml-special]
- ������[���ʉL���Ȃǂł��B���̂����u‘’“”‰†‡�v�͊�{�����ɂ�����܂��B
- [xhtml-symbol]
- ���w�L���Ȃǂł��B���̂����u…≠∞∴′″→←↑↓∈∋⊆⊇⊂⊃∪∩∧∨⇒⇔∀∃∠⊥∂∇≡√∝∫�v�ƃM���V�������uΑ�v�`�uΩ�v�uα�v�`�uω�v�͊�{�����ɂ�����܂��B
�����Ȑ���
- [xhtml-lat1]
- http://www.w3.org/TR/xhtml1/dtds.html#a_dtd_Latin-1_characters
- [xhtml-special]
- http://www.w3.org/TR/xhtml1/dtds.html#a_dtd_Special_characters
- [xhtml-symbol]
- http://www.w3.org/TR/xhtml1/dtds.html#a_dtd_Symbols
���[�U�[�͖ړI�ɉ����ĕ����Z�b�g�̓��e���J�X�^�}�C�Y�ł��܂��B
- ���e����2 �� Unicode �� Shift_JIS ����� HTML/XML �� �����Q�� �Ŏg���镶���Z�b�g�̓��e�́A�{�̃}�N���Ɠ����t�H���_�ɂ���g���q .enum �̃e�L�X�g�t�@�C���� UTF-16 �ŗ���Ă��܂��B�t�@�C�����̊g���q���������������`�F�b�N���X�g�̍��ږ��ƂȂ�܂��B
- HTML/XML �� ���̎Q�� �Ŏg���镶���Z�b�g�̓��e�́A�{�̃}�N���Ɠ����t�H���_�ɂ���g���q .ent �̃e�L�X�g�t�@�C���� HTML �̃G���e�B�e�B�Ƃ��ċL�q����Ă��܂��B������ W3C ���z�z���Ă������ �����̂܂g���܂��B�t�@�C�����̊g���q���������������`�F�b�N���X�g�̍��ږ��ƂȂ�܂��B
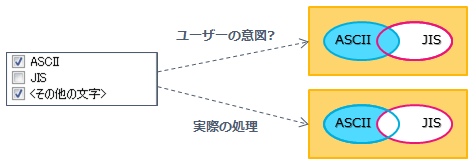
�_�C�A���O��� [<���̑��̕���>] ���I���ł���ꍇ�A�����Z�b�g�̓��e�݂͌��ɔr���I�łȂ���Ȃ�܂���B
- [<���̑��̕���>] ��I�������Ƃ��A�����I�ɂ́A�I�����Ă��Ȃ������Z�b�g�Ɋ܂܂�镶�����������S�Ă̕������ϊ�����܂��B���镶���Z�b�g�Ɋ܂܂�镶�������̕����Z�b�g�ɂ��܂܂�Ă���ƁA�ǂ��炩�Е��̕����Z�b�g�� [<���̑��̕���>] ���ɑI�������Ƃ��A���[�U�[�̈Ӑ}�ƈقȂ錋�ʂɂȂ肦�܂��B
- �Ⴆ�A�����Z�b�g�� [ASCII] �� [JIS] �� 2 �ɒP���������Ƃ��āA���������̕����Z�b�g�ɓ����������܂܂�Ă�����A���}�̂悤�Ȃ��ƂɂȂ�܂��B
- �g�������ɂ��@��ˑ�����������܂�
-
�Ώە����Z�b�g�� [Windows �@��ˑ�] �� [JIS X 0213 �g������] �̂ǂ��炩������I������ƕ\������܂��B������@��ˑ����� (NEC ���ꕶ���ENEC �I�� IBM �g�������EIBM �g������) �̂����AJIS X 0213:2004 �Ɏ��^����Ă�����̂� [JIS X 0213 �g������] �ɁA����ȊO�� [Windows �@��ˑ�] �Ɋ܂܂�Ă��܂��B���ׂĂ̋@��ˑ�������ϊ��ΏۂƂ���ɂ́A�`�F�b�N���X�g�� [Windows �@��ˑ�] �� [JIS X 0213 �g������] �̗�����I�����Ă��������B
- Shift_JIS �͈͊O�̕����́u�E�v�ɂȂ�܂�
-
Shift_JIS �̑Ώە����Z�b�g�� [JIS X 0213 �g������] ��I������ƕ\������܂��B���̏ꍇ�AWindows �� Shift_JIS (Microsoft CP932) �ŕ\���ł��Ȃ������́u\x8145�v(�u�E�v�A����) �ɉ����܂��B
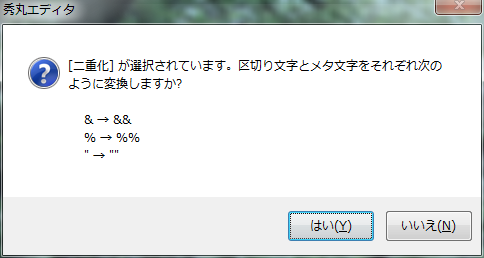
- [��d��] ���I������Ă��܂��B��蕶���ƃ��^���������ꂼ�ꎟ�̂悤�ɕϊ����܂���?
-
�Ώە������f���~�^�ƃ��^���������킹�� 2 �����ȏ゠��Ƃ��A[��d��] ��I�����ăG�X�P�[�v�^�A���G�X�P�[�v���悤�Ƃ���ƕ\������܂��B���̏ꍇ�A���ꂼ��̑Ώە������ʂɓ�d������܂� (��: �Ώە������u&%"�v�̂Ƃ��A�u&Say "%s".�v���u&&Say ""%%s"".�v)�B���̓��삪�Ӑ}�������̂Ȃ� [�͂�] ���A�L�����Z������ɂ� [������] �������Ă��������B